
 青少年在线精英教育平台
青少年在线精英教育平台
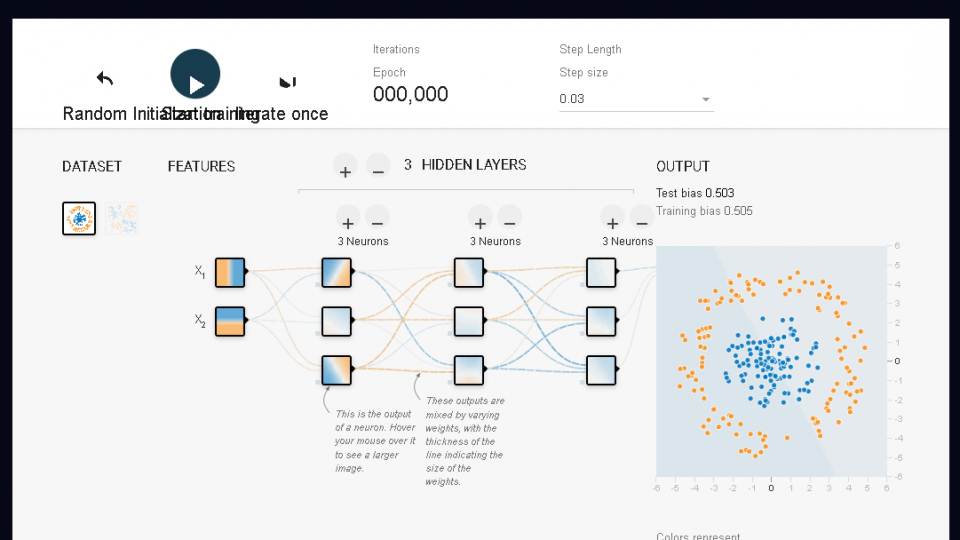


1. Use the default network architecture (three hidden layers with three neurons each) and try out several different step sizes. For each step size, record whether the training run succeeds and, if it does, how many iterations it takes. Does a larger step size always help? Or is a smaller one better?
The step sizes that worked for me were 0.03 and 0.1. The other ones either didn't work or were just to slow take from 2000-5000 epochs. No a bigger step size did not mean a faster time, sometimes the bigger step sizes would spazm out or just go to far ahead. And a smaller sttep size was just to slow.
2. Pick one of the two maps and design your own network architecture. Run a series of tests with different step sizes and record the training results. Share some interesting observations or insights you gained during the process.
I picked the first graph. I designed multiple architectures, but I found the perfect one. 4 hidden Layers, with 7 * 7 * 8 * 8 neurons in each of those hidden layers. The fastest time in iterations for this one was 21 epochs which was equal to the maxed out one with everything to the max. Some interesting observations was where I noticed that every new attempt the time in iterations/ephocs was different every single time.

- 人工智能教育专家亲自授课
- 源于斯坦福的人工智能思维
- 机器人和具身智能专业知识
WeChat & Official Accounts 微信&公众号

导师微信

里兰公众号